
Towards the Internet as a Public Infrastructure
Feed from C4R - Monday, November 20, 2023A Protocol of Fairness
Sergiu Nisioi, 2023
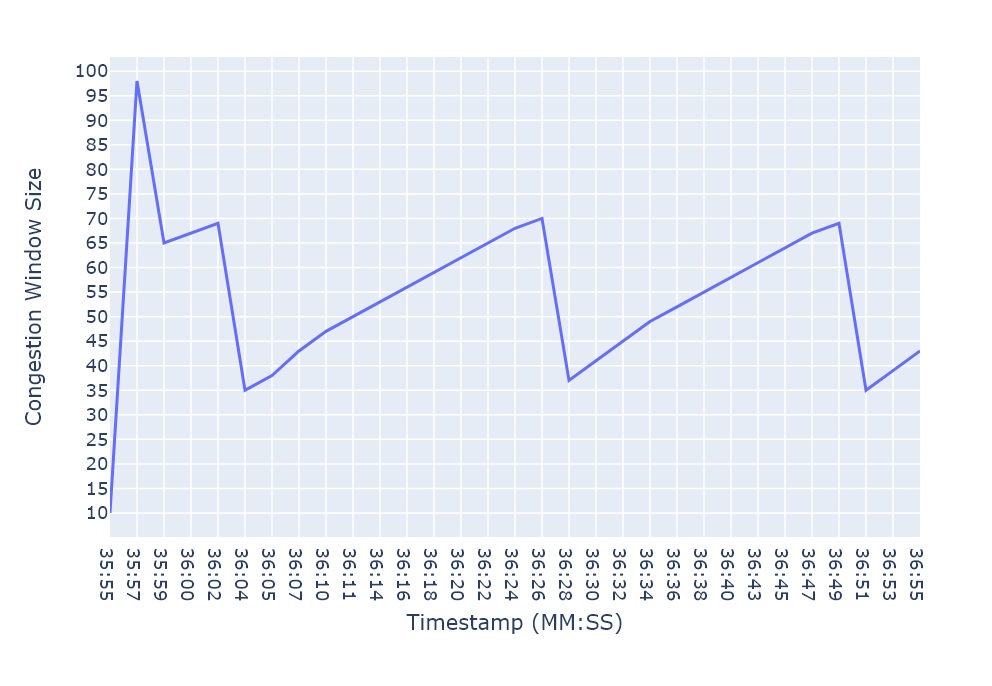 Additive Increase Multiplicative Decrease by TCP Reno. The chainsaw graph illustrates how a node renounces its network resource usage once it identifies congestion.
Additive Increase Multiplicative Decrease by TCP Reno. The chainsaw graph illustrates how a node renounces its network resource usage once it identifies congestion.
I would like to start this short essay with a metaphor from the Internet. It’s about a way of allocating resources (bandwidth) in a fair manner so that everyone (both home-users and large organizations) can use the network. The network represents the Internet and it is made of nodes (phones, laptops, printers, servers, connected devices) and middleboxes (routers, switches, proxies, firewalls etc.) which are engaged in a time-consuming process of reading and processing packets coming from the nodes. Sometimes nodes are sending packets at very high rates. The middleboxes get congested and have to drop the surplus packets they cannot handle. When this happens, nodes usually resend the dropped packets which further aggravates the congestion, thus making the middleboxes even slower. This situation is called Congestion collapse and it was firstly observed in the NSFNET in October 1986 when the transmission rates dropped by 800 times. A most elementary solution to the Congestion collapse problem would be to assign a special node that would be responsible for limiting the traffic of the other existing nodes. But this would actually prove to be an impractical and impossible solution, since nodes have a dynamic behavior and the network has different capacities at different times. A solution is to establish a protocol (i.e., a set of common rules) so that nodes can figure out by themselves if the network is overloaded and to reduce the amount of resource consumption. The rules must be fair and must allow new peers to join the network without discriminating in favor of other ones. The Internet Engineering Task Force (IETF) is a collective responsible for designing the rules and establishing the Internet protocols. Transmission Control Protocol (TCP) is currently one of the most widely used protocols of the Internet (probably the one you are using to read this text in your browser). This protocol has been proposed in 1981 and has sustained several modifications since then. TCP is responsible for governing the transmission of data and to ensure the data arrives at the destination in order, without errors, without flooding a receiver, and without congesting the entire network.
The underlying principle of the congestion control mechanism is called Additive Increase Multiplicative Decrease (AIMD). More specifically, each node starts consuming resources gradually, increasing the rate of consumption additively one by one. As soon as congestion is detected, the rate is decreased multiplicatively (let’s assume by half), giving back to the network half of its resources. See a visualization of this process in the figure above. This allows new nodes to join in and gives more time to the middleboxes to complete their work without dropping any new incoming messages. But as new nodes join in, the network can get congested again, and so each node will give back to the network half of its resources which will free up even more resources to the entire network. After going through this cycle multiple times, the network will reach a stable state where the resources are fairly distributed across all the nodes.
The Internet
 Cybersyn operations room. CGI Photograph by Rama, Wikimedia Commons, Cc-by-sa-2.0-fr
Cybersyn operations room. CGI Photograph by Rama, Wikimedia Commons, Cc-by-sa-2.0-fr
The Internet today still preserves the relics of a decentralized design from the early days, as far back as the ’60s, when the major work of designing its layers came out from state-funded research and the ownership of the infrastructure was public . Similarly to how the welfare state emerged as a response to the socialist world , so the birth of the computer networks in the US can be regarded as a government response to the Soviet accomplishments in science, cybernetics, and space travel. In the socialist world, computer networks were developed with the greater purpose of conducting economic planning, see for example ОГАС (Statewide Automated Management System) developed in the ’60s in the Soviet Union or the Cybersyn project in Allende’s Chile . In Romania, the first computer networks were developed in the ’70s as part of RENOD/RENAC and CAMELEON (Connectivity, Adaptability, Modularity, Extensibility, Local, Efficiency, Openness, Networking) projects and were used for communicating information from factories such as the now defunct and privatized Laminated Electric Cable Company [Compania de Cablu Electric Laminat] in Zalău to the planning authorities in Bucharest.
However, the network of networks that we all use today is very far from the ideas of decentralization and public ownership. In fact, the Internet infrastructure (NSFNET) has been privatized in the ’90s, like many different public services across the world. From a public good of the US National Science Foundation (NSF) to a handful of US Corporations . This type of ownership monopoly has not changed over the years, on the contrary, it has been replicated across the world in all the capitalist countries. In the early days of the ’90s the Internet in Romania was provided by RNC (National Research Network) and by many small neighborhood companies. Hacking culture, cracking, and file sharing was widely popular . However, as the internet became more and more an instrument for financial gainings and money-making, and as the free-market became more powerful, extending to infiltrate post-socialist countries, these neighborhood networks have been gradually taken over by larger companies which have been mostly taken over by international corporations, leading to currently 5 major Internet Service Providers.
In order for the Internet monopolies to maintain their large-scale networks and ensure customer satisfaction [sic], special hardware middleboxes are created specifically to process the millions of packets going through them every second. These devices are usually proprietary, come at very high costs, and special contracts tie a company’s infrastructure to a device manufacturer. Unlike the ideas of reproductible open research which fuel innovation and helps towards a better Internet, in this system, the capitalist chains of relations converge towards tech monopolies which translate to high degree of surveillance, prohibitively high internet prices for some end-users, and the exclusion of certain groups from the benefits of the Internet.
Beyond the Physical Infrastructure
 (C) SayCheeeeeese, Public domain, via Wikimedia Commons
(C) SayCheeeeeese, Public domain, via Wikimedia Commons
The privatization of the physical infrastructure was lobbied by companies because more and more willing-to-pay users wanted to join this network. From a state-funded research and non-profit entity, the network quickly became a market that was promoted as more democratic, where any small manufacturer can sell its products and therefore its work to the entire world. However, in the capitalist mode of production, it turned into a blind venture investment in startups that promised a new economy. Inevitably, the dot-com bubble crashed in the early 2000s. Survivors of the crash became tech monopolies who control up to this day the content being delivered, which products are promoted, the hosting infrastructure, the means to search online content, and the general information flow. It is interesting how the ideas of hacking (as tinkering and repurposing) and the hacking culture of the nineties was captured by the capitalist mode of production and re-directed towards a cult of innovation . Anything that was not aligned with for-profit activities, such as media sharing, cracking, reverse engineering, and other forms of tinkering, were criminalized with the help of law enforcement. In this hostile context, the open culture of hacking was captured and shattered by capitalist production and ownership.
The business models that emerged after the dot-com bubble are being driven by a paid subscription, by charging users with their data, or by both. Something we are very familiar with today. Media companies found new legislative methods to forbid music and films from being redistributed. Similarly, academic publishers rent their author’s PDFs at prohibitively-high prices just for being hosted on their websites. Unlike physical objects that are consumed and enter a recycling life, digital objects can be recreated indefinitely and new profits can be obtained out of them regardless of the time and effort invested in their creation. Human laborers annotating data for training artificial intelligence are paid only once with an extremely low wage, but how much more can be extracted by indefinitely mining that data? Today, the largest tech companies drive their profits from advertisements, marketing, the manipulation of desire, and behavioral prediction and the Internet is the space where all of this happens. Far from being a public space, the Internet is a highly privatized one both in terms of physical and software infrastructures.
Steps Towards Digital Literacy
Most if not all the present technological advancements emerged from state-funded open and reproducible research. Usually omitted and treated as a historical event, deprived of its political and economic meaning, this fact should not be forgotten when re-envisioning and rebuilding the Internet as a collective open resource. Neither should be the fact that the physical infrastructure is grounded in the natural resources of the planet. As long as the internet is not regarded as a public good, but it remains privately owned by profit-oriented entities, then our alternatives are very little. But let’s not abandon all hopes as we can at least strive for digital emancipation, to gain more knowledge on how the underlying technologies function, to encourage hacking, and to find platforms that respect user privacy and do not treat users as a source of data to be mined. To start somewhere, maybe the first step would be to gather some comrades and convince them to start tinkering together. See the online collaborative tools published by Framasoft or CryptPad for de-googling the internet. Consider trying alternative open services such as peertube - a peer-to-peer protocol where videos are both viewed and uploaded to other users at the same time. Or Mastodon - an alternative to extractivist social media based on ActivityPub protocol. Try to join an existing instance to see how it looks like. Most importantly, join with a couple of friends. Collectives such as systerserver and riseup offer services for activists and people who are interested in digital emancipation. Experiment with alternative ways of accessing the internet using privacy-focused tools such as I2P, Tor, or Freenet. Using alternative software and services might be a good place to start, but if you wish to gain technical knowledge, among the first things to try would be to install a free and open-source operating system, Linux-based or BSD. Such a radical transition on your personal computer might be shocking or impractical, but you can try to install it on a Raspberry Pi or on some old machine that you recover from scrap. It doesn’t have to be a very fast up-to-date computer, Linux distributions can be lightweight enough to run on an old machine with few resources. This can become your low-fi server and it can give you an idea of what running a Unix system is about.
Then you should try to self-host a service, which can mean a lot of work, but consider it more of a process to acquire digital skills than creating something for providing reliable services. If you went on the path of recovering an old computer from scrap, the best thing to host might just be a static website . If the machine is somewhat comparable to your PC, then the easiest way to start self-hosting is to install yunohost on the computer that you designate as a server. Yunohost is a Debian-based operating system that comes with a web interface and a set of pre-configured services such as WordPress, Nextcloud, Etherpad, etc. These processes can be done on a computer that does not need to be connected to the Internet. You can access the server by connecting it on your local network via WiFi or cable. This is a good way to learn how to configure a server and how to install services. It also gives a better understanding of what sort of configurations can be done at the level of a local network. Self-hosting a reliable service is difficult, do not expect everything to work perfectly from the start. Treat this as a learning process. Play with the server locally. If you wish to share the content with a small group of friends, create a Mesh VPN Network by installing zerotier on your devices. This will create a virtual network that will allow you and your friends to connect to your server from any device that has joined the same virtual network. For true Internet connectivity, you can use a dynamic DNS from your internet service provider or obtain a domain name and configure it to point to your server. After obtaining a domain name, it is a good habit to also obtain a certificate for your name that can be used to encrypt connections between your server and the users through HTTPS. You can obtain a free certificate from Let’s Encrypt. DNS is responsible for mapping the human-readable name to an IP address. A simple way of blocking ads and trackers on your local network at home is to use a blacklist with all the well-known trackers and their domain names. A pi-hole is exactly that, a tiny Raspberry Pi that you put on your local network to act as a fake DNS server. Every time your browser makes a request to a tracker the pi-hole will return a false IP address, so it will not be able to access pages from the blacklisted domains. After gaining more experience with configuring a server, you may even consider self-hosting your own Mastodon instance and invite your friends or connect with other instances.
In every step above, keep a journal of what worked or not, this is a way of redistributing knowledge. And do not forget that to achieve systemic change we must put pressure on the current system, strike against digital imperialism, and demand the Internet to become a public infrastructure in the interest of all the people.
Sergiu Nisioi is a research scientist and professor at the University of Bucharest where he teaches Computer Networking, Machine Translation, and Archaeology of Intelligent Machines - an experi-mental course in the history of artificial intelligence. His research covers areas related to computational linguistics, artificial learning theory, and the history of cybernetics in socialism.
A text commissioned by tranzit.ro, as part of a mapping of resilient practices in Romania and Eastern Europe, in the frame of C4R project.